本项目涉及数据清洗及分析时候的思路,如果仅在CSDN中看,可能会显得有些乱,建议去本人和鲸社区对应的项目中去查看,源代码和数据集都是免费下载的。
声明:本项目的成果可无偿分享,用于学习交流。但请勿用于商业用途或倒卖。一经发现情节严重者,将依法追究相关责任。
1.项目背景悉尼作为澳大利亚最大的城市之一,其房地产市场一直是国内外投资者和居民关注的焦点,近年来,随着人口增长、城市化进程加速,以及经济环境的变化,悉尼及其周边地区的房产需求和价格波动频繁。为了更好地理解这一市场的现状与趋势,本项目针对悉尼房地产市场进行了全面的数据分析,旨在通过科学的手段挖掘市场特征,为房地产投资决策和政策制定提供数据支持。
2.数据说明 字段说明数据集包含 1000 条记录 和 42 个字段,值得注意的是,存在多个缺失特征,如房产的估计价格、与估计价格相关的置信水平等,这些特征不足以进行全面分析,只能删除;还注意到本应该是数值型的特征,如estimated_value,却是字符型,这些都说明,这个数据可能会很难分析。
通过输出前五行数据,发现一些特征也需要处理,总结下来就是:
将 last_sold_date 转为标准日期格式,去掉时间戳和引号。
清理 floor_area,将 “Unavailable” 转为缺失值,并与 floor_area_num 统一处理。
检查 house_type 和 property_type,如果重复则保留 property_type,删除 house_type。
删除 photo_count,字段对后续分析无用。
删除 street_address,地理分析已经由 state, postcode, lat, lon 覆盖。
删除 fullSuburb,与 suburb 重复,仅保留 suburb。
删除 land_size,与 land_size_num 重复,仅保留数值型 land_size_num。
删除 sales_history,嵌套 JSON 数据内容已提取。
检查 land_size_unit,如果所有单位均为平方米,删除此字段。
删除 avm_estimate_lastUpdated,字段与缺失的估价字段相关,无实际分析价值。
保留 estimated_price 系列字段(estimated_value, estimated_value_high, estimated_value_low 等),后续分析后决定保留或删除。
将 offMarket 转为数值型(0 和 1)。
land_size_unit中唯一值情况:[’ m²’ ‘2 m²’ ‘1 m²’],单位应该就是m²了,'2 m²' 和 '1 m²' 应该是错误的单位,所以直接删除land_size_unit。
通过equals检查发现 house_type 和 property_type 完全重复,故直接删除 house_type列。
equals 是 Pandas 提供的一种方法,用于逐元素比较两个 Series 或两个 DataFrame 是否完全相同。它特别适合用来检查两个列的数据是否一致。
同样的,将 floor_area 列中Unavailable转为缺失值后, floor_area 和 floor_area_num 完全重复,故直接删除 floor_area 列。



房屋有两种类型,Unit 和 House。
state只有一个唯一值,对分析没用,故直接删除。
last_sold_agency唯一值数量较多,难以提取有意义的信息,故删除。
suburb也是唯一值太多了,后续建模分析的时候也是要删除的,但是目前可以保留,万一处理那些缺失值能起作用。
estimated_value 中undefined - undefined视为缺失值,而且怀疑它其他的值,和estimated_value_high、estimated_value_low是一致的。
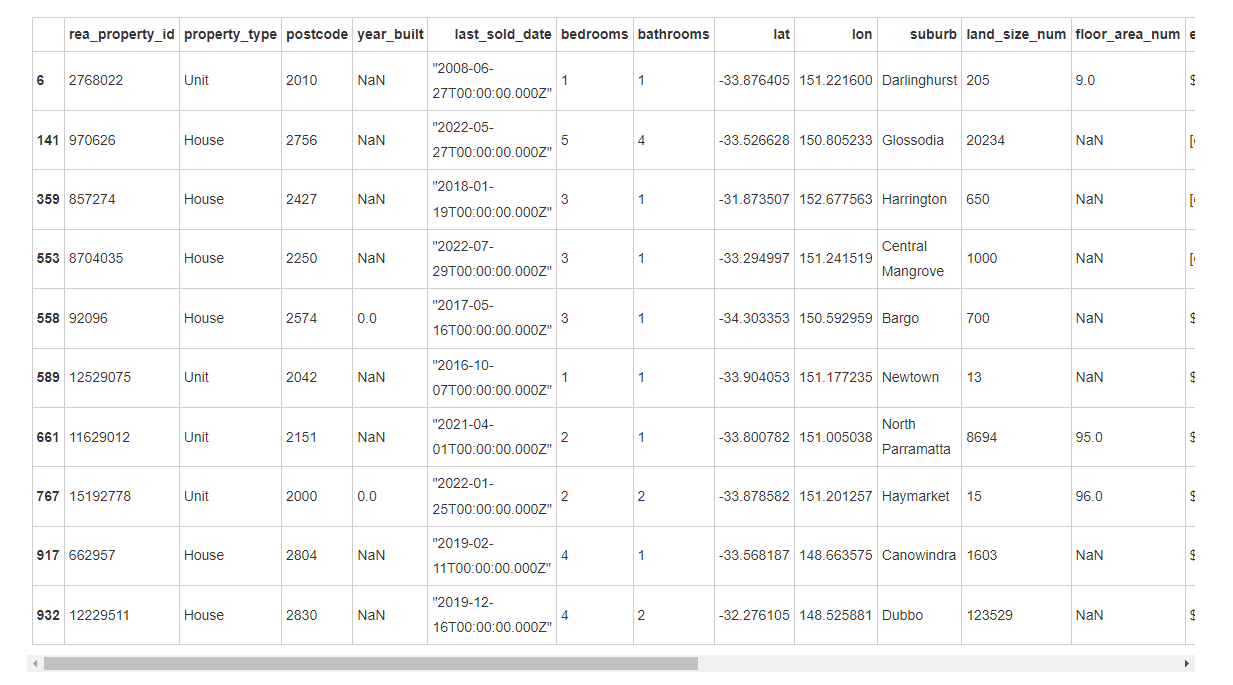
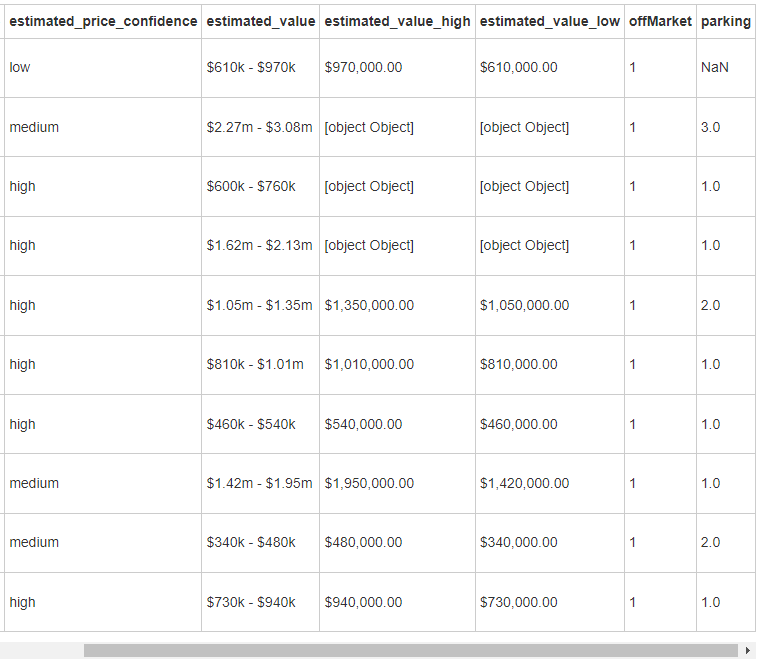
头疼,这些数据缺失值是真的多,在 estimated_price 中仅10条非缺失值中,year_built 不是缺失值就是 0,然后注意到,estimated_price 中 存在 [object Object] ,但是还是有好消息的,那就是 estimated_value 和 estimated_price_confidence 都是存在的,这就好办了,当为 medium 时,取对应的 estimated_value 中位数,当为 high 时,取最大值,做完这些操作后,删除 estimated_price_confidence 、estimated_value 、estimated_value_high 、 estimated_value_low 。
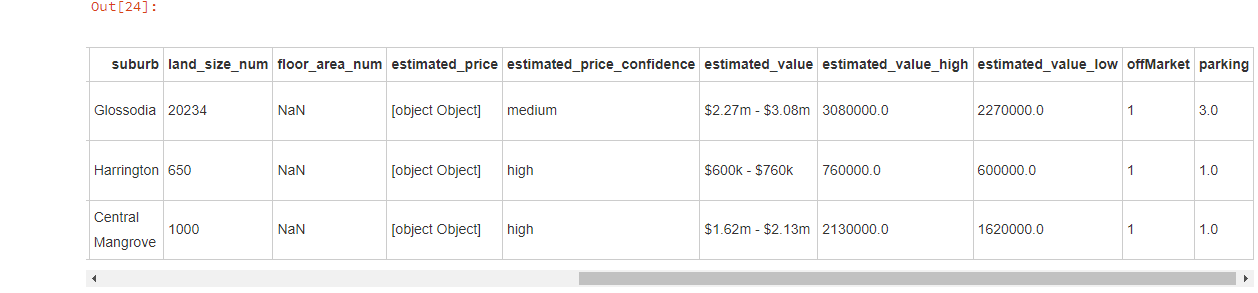
可以看到,已经正确的填充 estimated_value_high 和 estimated_value_low,接下来只要处理 estimated_price 即可。
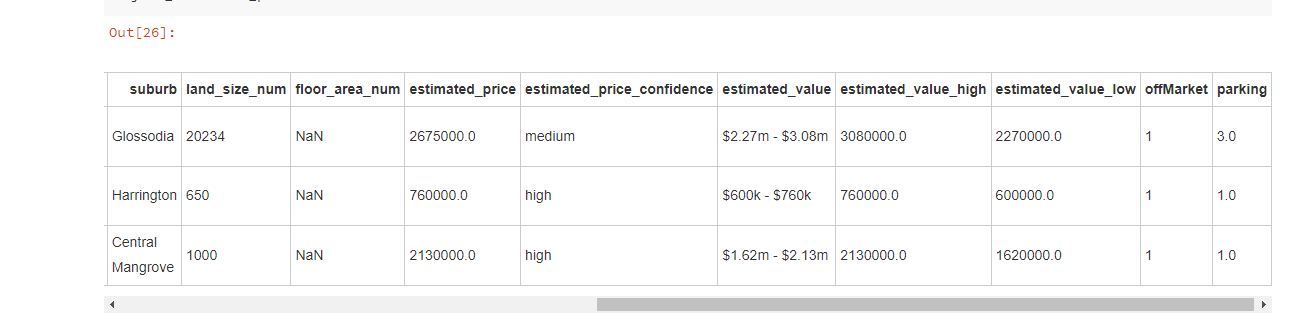
终于填充完毕了,现在把这个填充后的数据填进原始data中,并且删除其他的特征。
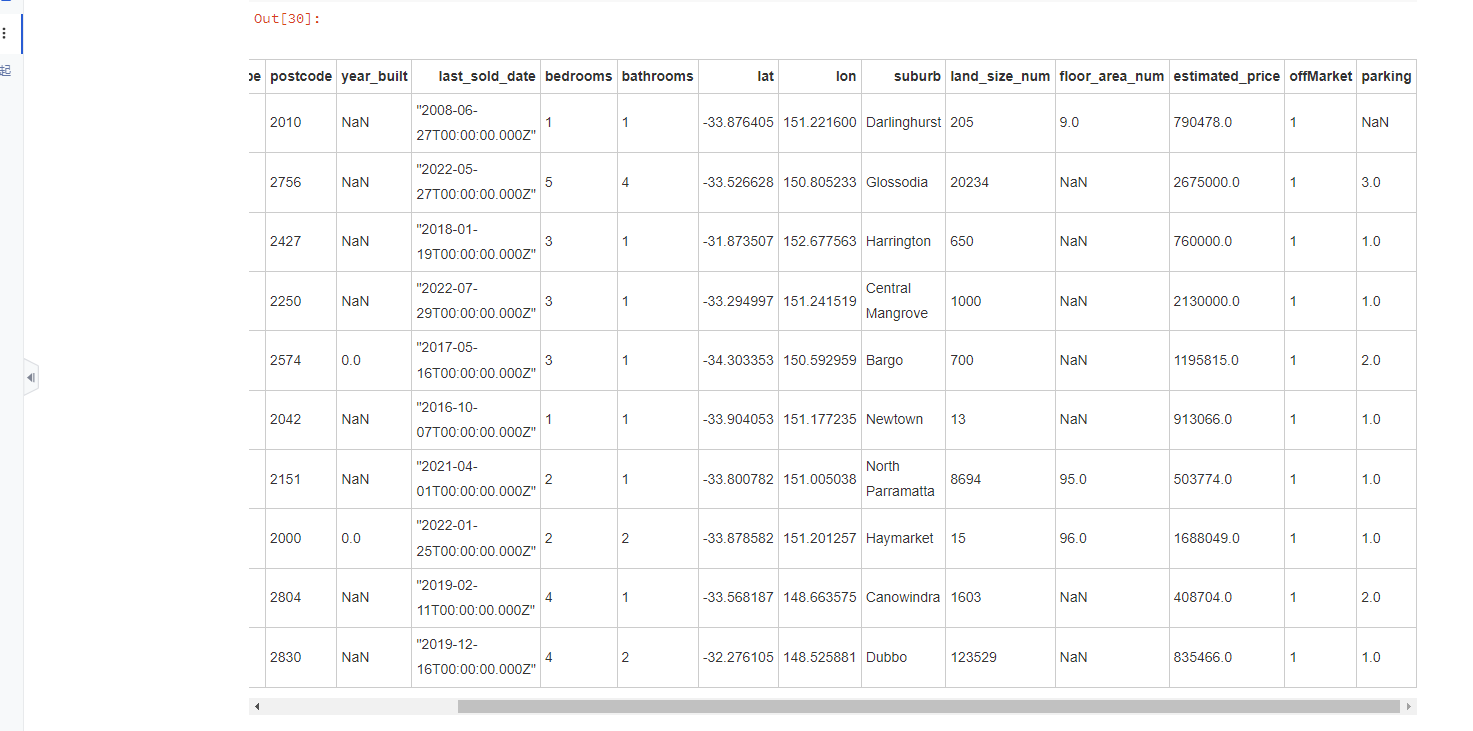
终于弄完了,现在要开始处理缺失值了,像year_built把0也弄成缺失值后看一下,当然也检查一下其他数值型特征是否也存在用数值来代替缺失值的情况,
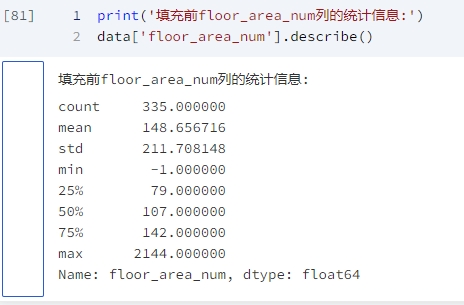
列 floor_area_num 存在负值:1 条,将列 floor_area_num 中的负值设置为缺失值。
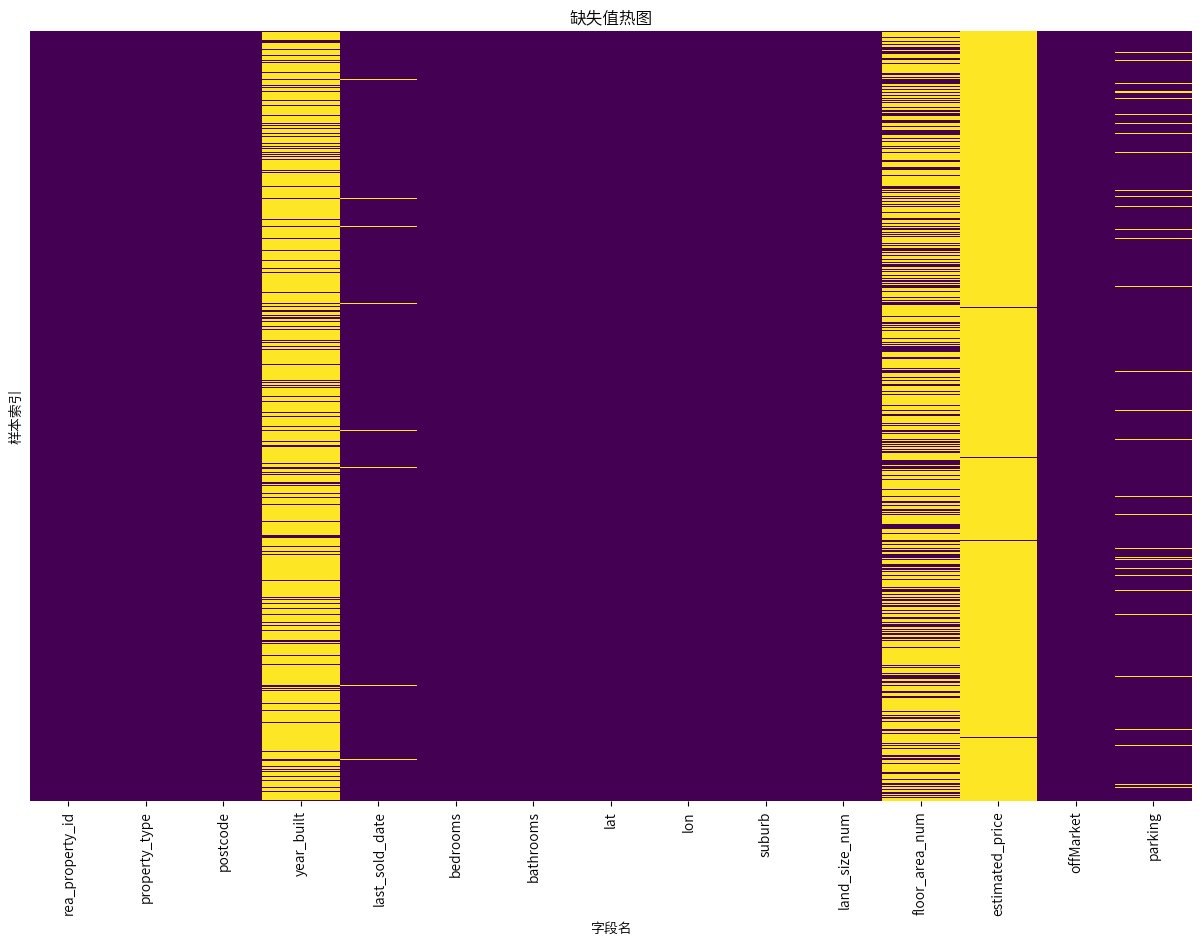
不存在某行缺失值特别多的情况,但是还是直接删除year_built和last_sold_date中缺失的10行数据,然后把last_sold_date转为日期形式。

现在还剩floor_area_num、parking、estimated_price的缺失值没处理了,借助postcode、suburb来看看能不能处理,parking的话,就看看能不能用0填充,最麻烦的就是estimated_price了,删除也不是,不删除也不是,暂时先不处理,等后续分析了看,能不能挖掘一些有用的信息再去处理它。
44.51%的缺失值在房产的类型、房产的邮政编码、房产所在郊区都保持一致,针对这一部分数据,采用直接用分组后的中位数来填充。
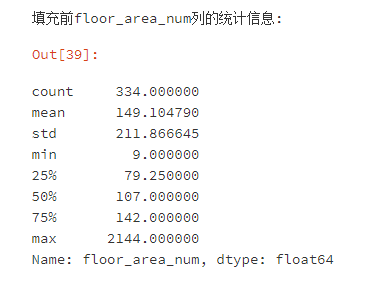

平均值略有下降,可能因为填充的中位数较整体平均值小。
标准差稍微下降,表明填补后数据分布更均匀。
但是总体而言,中位数填充后的统计数据非常接近填充前,说明填补方式有效,未引入明显偏差,
填补后的缺失值比例: 36.77%,剩下的缺失值,就考虑用KNN方法来填充了。

标准差从 211.87 降到 169.25,说明数据分布更加集中。
四分位数有明显上升,但最值没变,未影响数据的极值范围。
均值接近原始数据分布,总的看来,是能够接受这个填充结果的。

最小值是1,因此更能确定用0去填充parking列的缺失值。
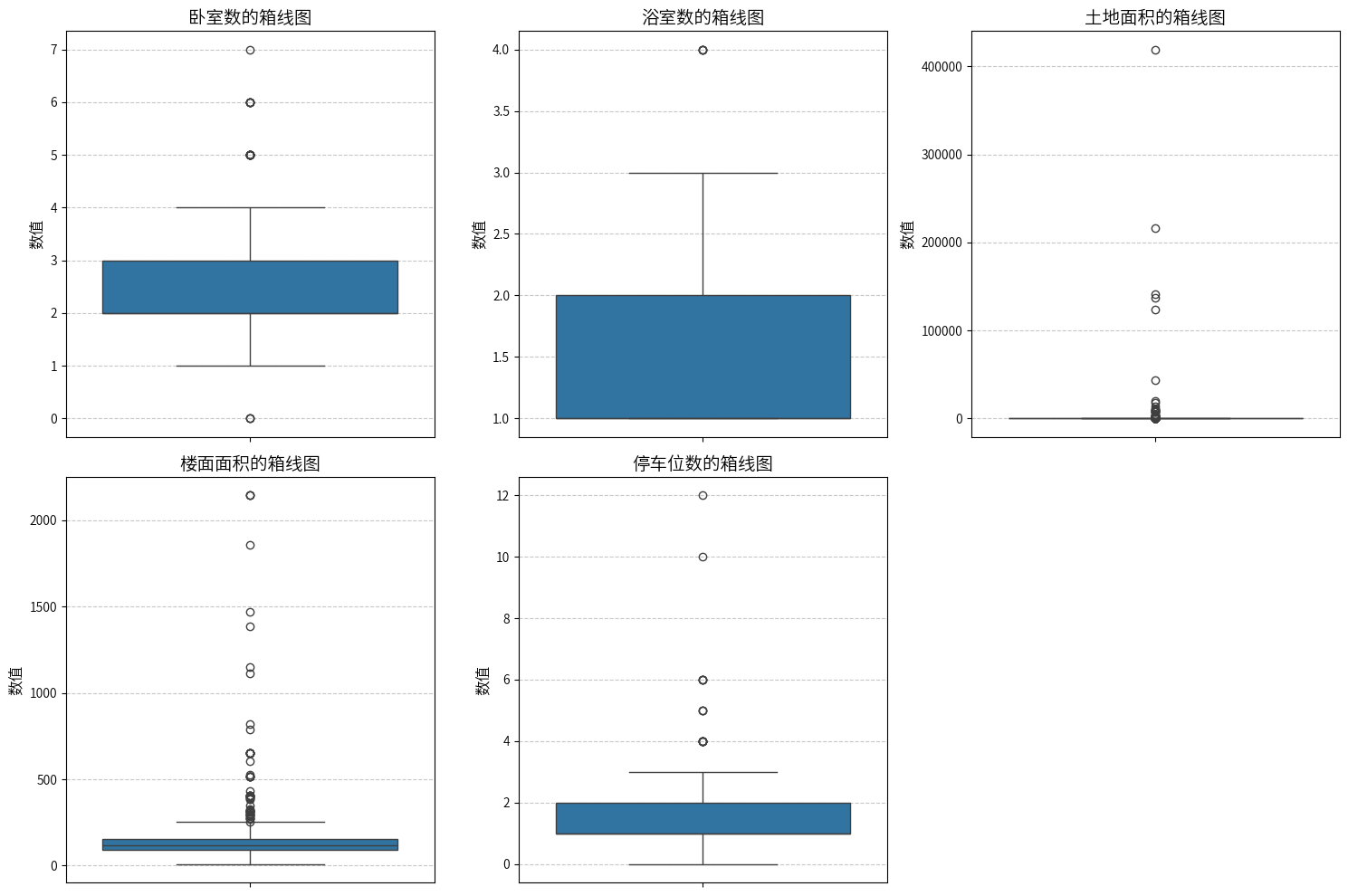
这些数值有些夸张了,土地面积40万平方米,按土地面积降序输出看一下是怎么回事。
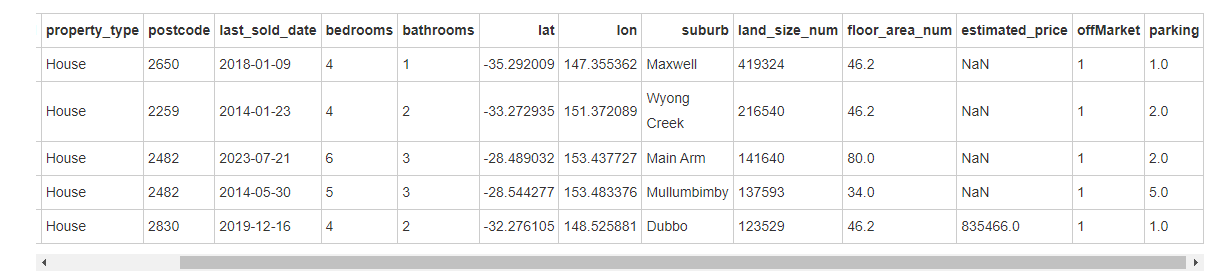
可以认定这些是异常值了,因此,使用IQR来处理异常值,将异常值替换为上下界值,避免对数据分布产生较大影响,但是要注意,有些特征是整数型的,处理的时候,需要考虑取整的情况,不然会这样:
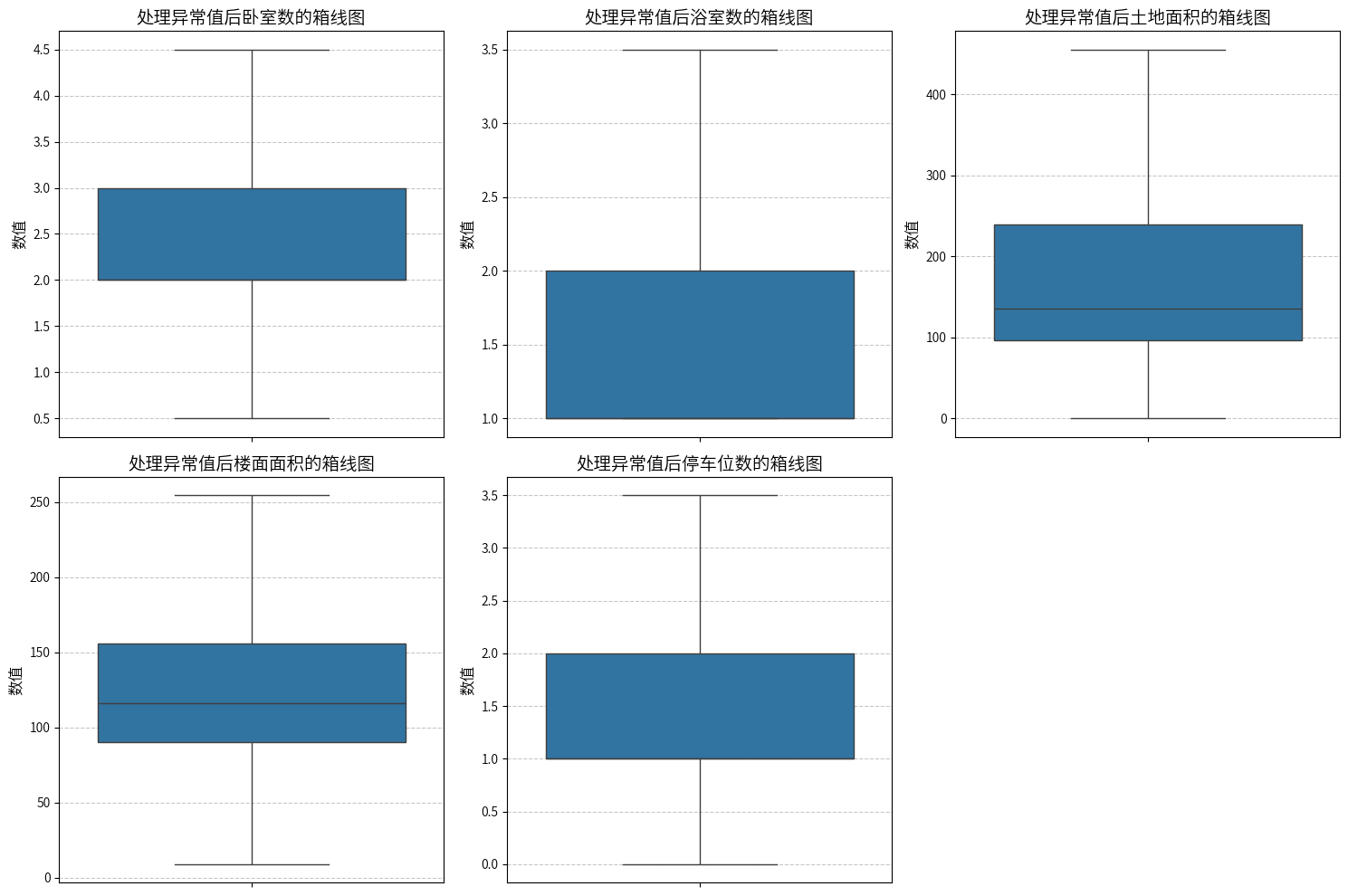
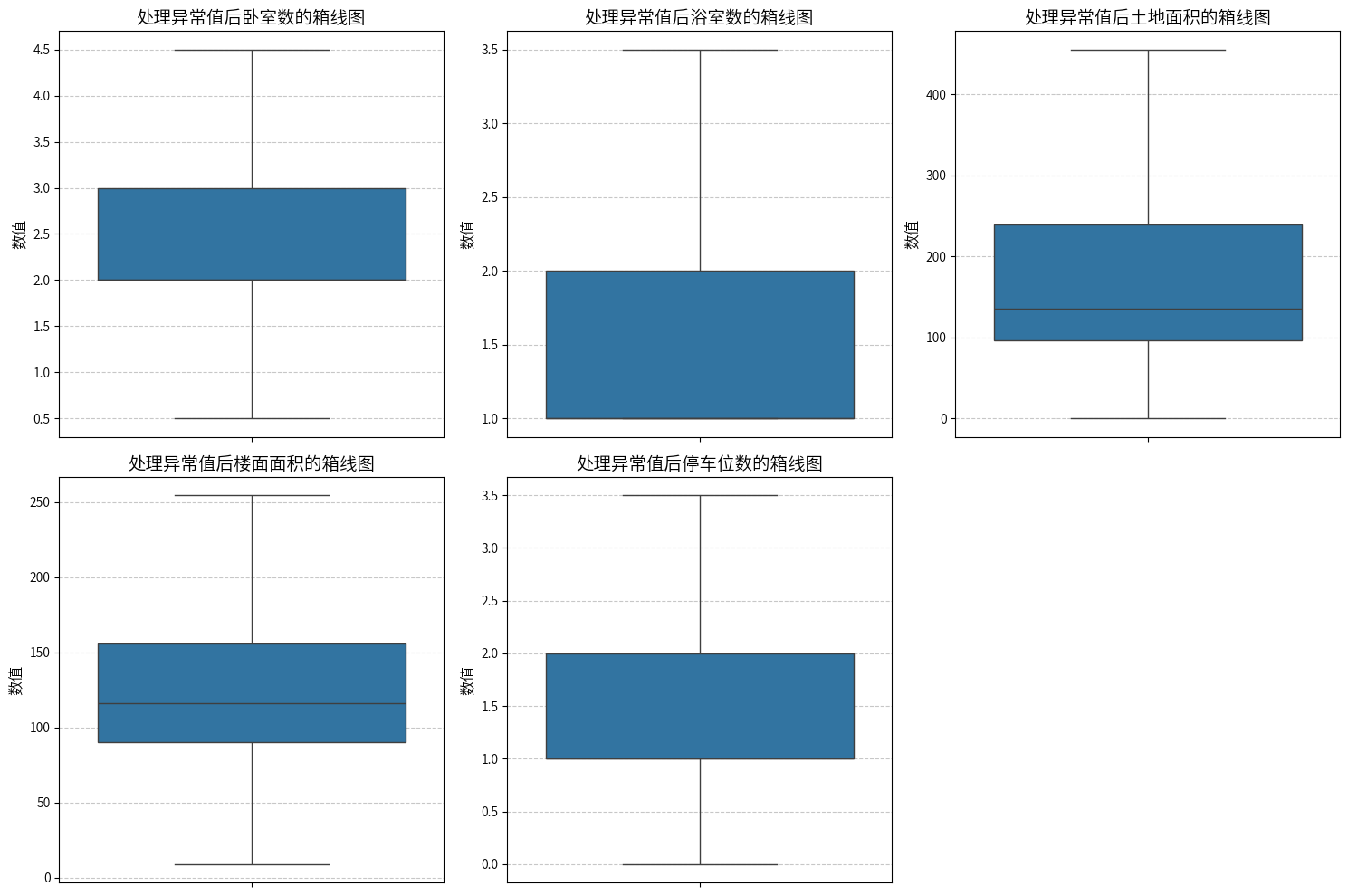
到这里,基本上就处理完毕了,总所周知,房价和房屋面积是呈相关的,所以,这里可以借助SMOTER + 模型预测的方式,去填充房价的缺失值,并且提供预测的置信区间,当然这一步仅仅是一个假设性处理,如果填充效果不理想的话,还是会选择删除estimated_price特征。
运行该段代码,会报一个警告:
smote = SMOTE() x_resampled, y_resampled = smote.sample(x_train, y_train)警告内容:
2024-11-26 03:37:40,265:INFO:SMOTE: Running sampling via ('SMOTE', "{'proportion': 1.0, 'n_neighbors': 5, 'nn_params': {}, 'n_jobs': 1, 'ss_params': {'n_dim': 2, 'simplex_sampling': 'random', 'within_simplex_sampling': 'random', 'gaussian_component': {}}, 'random_state': None, 'class_name': 'SMOTE'}") 2024-11-26 03:37:40,266:INFO:SMOTE: Too few minority samples for sampling这个警告的意思是样本量太少,无法生成有效的合成数据,这个思路不行,那就直接先进行斯皮尔曼相关性分析,然后选择相关性强的数据构建贝叶斯模型。
correlation = data[['bedrooms', 'bathrooms', 'land_size_num', 'floor_area_num', 'parking', 'estimated_price']].corr(method='spearman') print("与estimated_price相关性矩阵:") print(correlation['estimated_price']) 与estimated_price相关性矩阵: bedrooms 0.068784 bathrooms 0.539360 land_size_num -0.141677 floor_area_num 0.090909 parking 0.246755 estimated_price 1.000000 Name: estimated_price, dtype: float64选择bathrooms和parking作为特征去预测estimated_price,看看效果咋样。
# 提取特征和目标 features = ['bathrooms', 'parking'] target = 'estimated_price' # 筛选非缺失值样本 data_train = data[data[target].notna()] data_predict = data[data[target].isna()] x_train = data_train[features].fillna(0) y_train = data_train[target] x_predict = data_predict[features].fillna(0) # 建立贝叶斯回归模型 bayes_model = BayesianRidge() bayes_model.fit(x_train, y_train) # 预测缺失值及置信区间 predicted_values = bayes_model.predict(x_predict) data.loc[data[target].isna(), target] = predicted_values结果预测的效果很差:
房产类型 (property_type):两种类型,以 Unit 为主(占 79.5%)。
邮政编码 (postcode):范围 2000-2870,集中在新南威尔士州 (NSW)。
上次出售时间 (last_sold_date):时间分布广泛,从 1992 年到 2023 年,集中于 2019 年到 2022 年。
卧室数 (bedrooms):大多数房产有 2-3 间卧室,最大为 4 间,平均为 2.38。
浴室数 (bathrooms):平均为 1.49 间,主要集中在 1-2 间,最大为 4 间。
土地面积 (land_size_num):范围 0-455㎡,中位数为 135㎡,显示中小型房产为主。
楼面面积 (floor_area_num):均值为 128.76㎡,四分位范围 90㎡-155.8㎡。
停车位 (parking):平均为 1.3 个,75% 的房产至少有 1 个停车位,最大为 4 个。
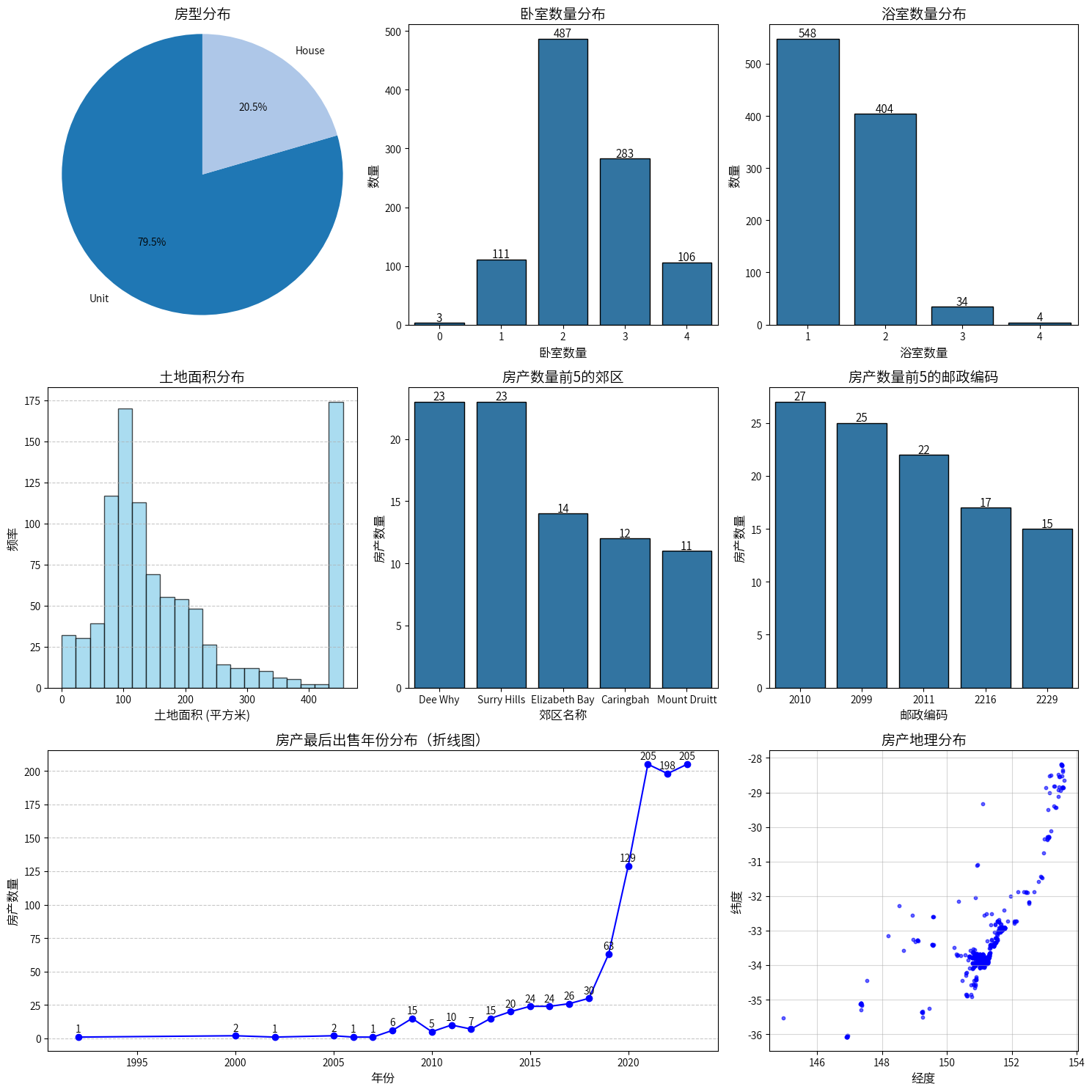
数据反映了悉尼及其周边区域的房地产市场特点,房产类型以公寓(Unit)为主,较小面积和较少卧室房产占据主要市场,最近几年交易活跃度显著上升。
6.聚类分析 6.1数据预处理选择’land_size_num’, ‘bedrooms’, ‘bathrooms’, ‘floor_area_num’, ‘lat’, 'lon’这些特征进行聚类,首先先进行标准化处理。
6.2确定聚类数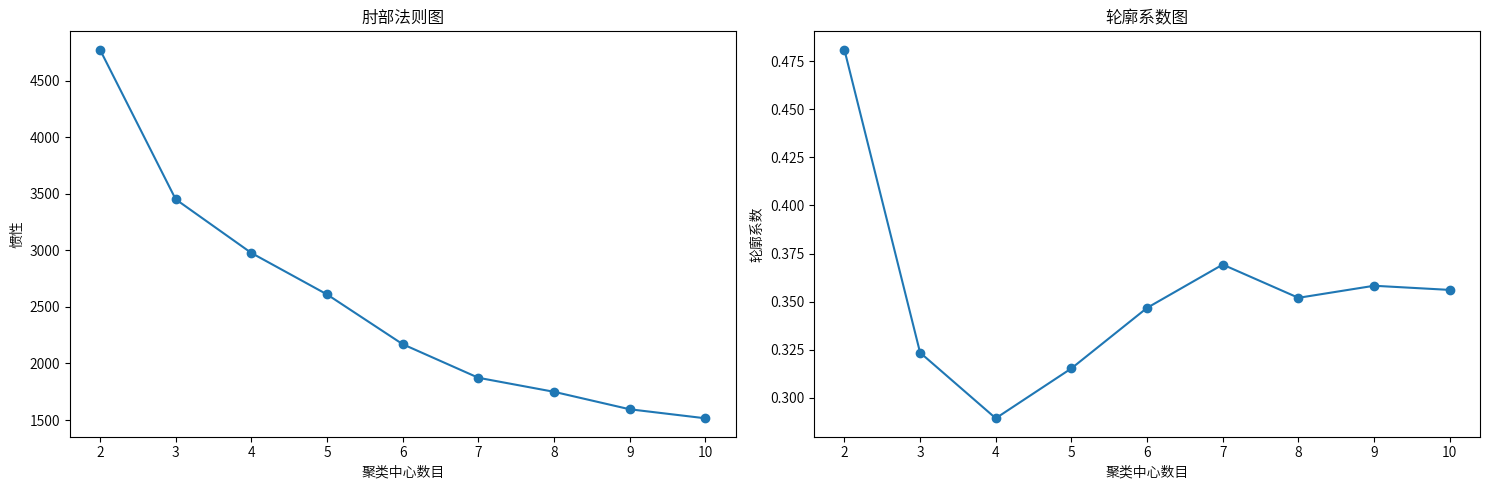
这里的话,我不确定究竟是选择3类还是6类、7类,如果选择6类、7类的话,虽然下降明显平稳,但是聚类数可能会过多,可能会导致过拟合现象,即某些类只是由于算法强行分割导致的,而不是实际存在的有意义分组。这里的话,我就选择都绘制一下,然后用pca降维展示哪一类更好
这是分成3类:
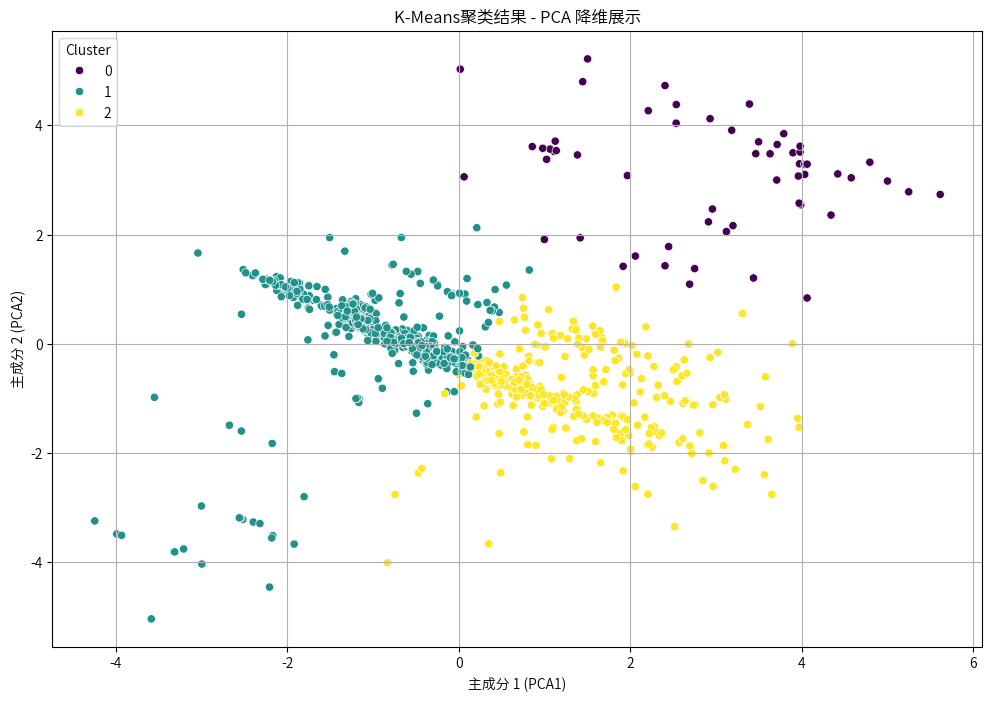
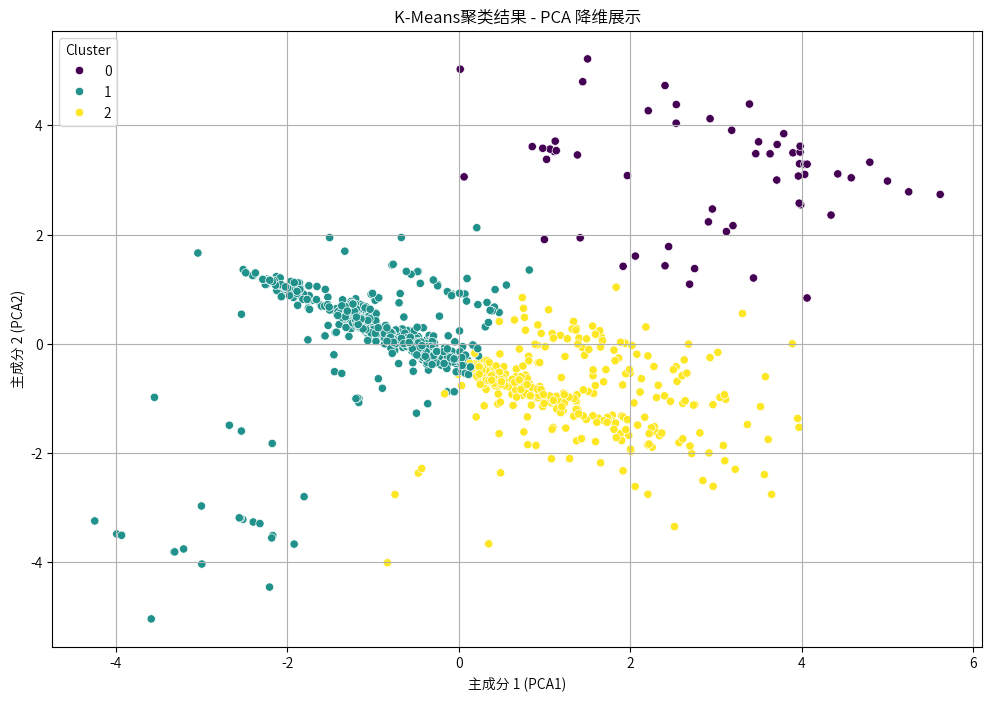
根据百度百科,查到悉尼的城市中心坐标为南纬33°51’、东经151°12′,这里可以结合Haversine公式,用于计算地球表面两点之间的最短距离(大圆距离),可以通过经纬度计算两地间的球面距离,这里用它来计算3类经纬度距离悉尼城市中心的距离。
d
=
2
R
⋅
arcsin
(
sin
2
(
Δ
ϕ
2
)
+
cos
(
ϕ
1
)
⋅
cos
(
ϕ
2
)
⋅
sin
2
(
Δ
λ
2
)
)
d = 2R \cdot \arcsin\left(\sqrt{\sin^2\left(\frac{\Delta \phi}{2}\right) + \cos(\phi_1) \cdot \cos(\phi_2) \cdot \sin^2\left(\frac{\Delta \lambda}{2}\right)}\right)
d=2R⋅arcsin(sin2(2Δϕ)+cos(ϕ1)⋅cos(ϕ2)⋅sin2(2Δλ))
其中:
d d d 是两点之间的球面距离(沿着地球表面测量)。
R R R 是地球的平均半径(通常取 6371公里)。
ϕ 1 , ϕ 2 \phi_1, \phi_2 ϕ1,ϕ2 是两点的纬度,以弧度表示。
λ 1 , λ 2 \lambda_1, \lambda_2 λ1,λ2 是两点的经度,以弧度表示。
Δ ϕ = ϕ 2 − ϕ 1 \Delta \phi = \phi_2 - \phi_1 Δϕ=ϕ2−ϕ1 是两点纬度差。
Δ λ = λ 2 − λ 1 \Delta \lambda = \lambda_2 - \lambda_1 Δλ=λ2−λ1 是两点经度差。
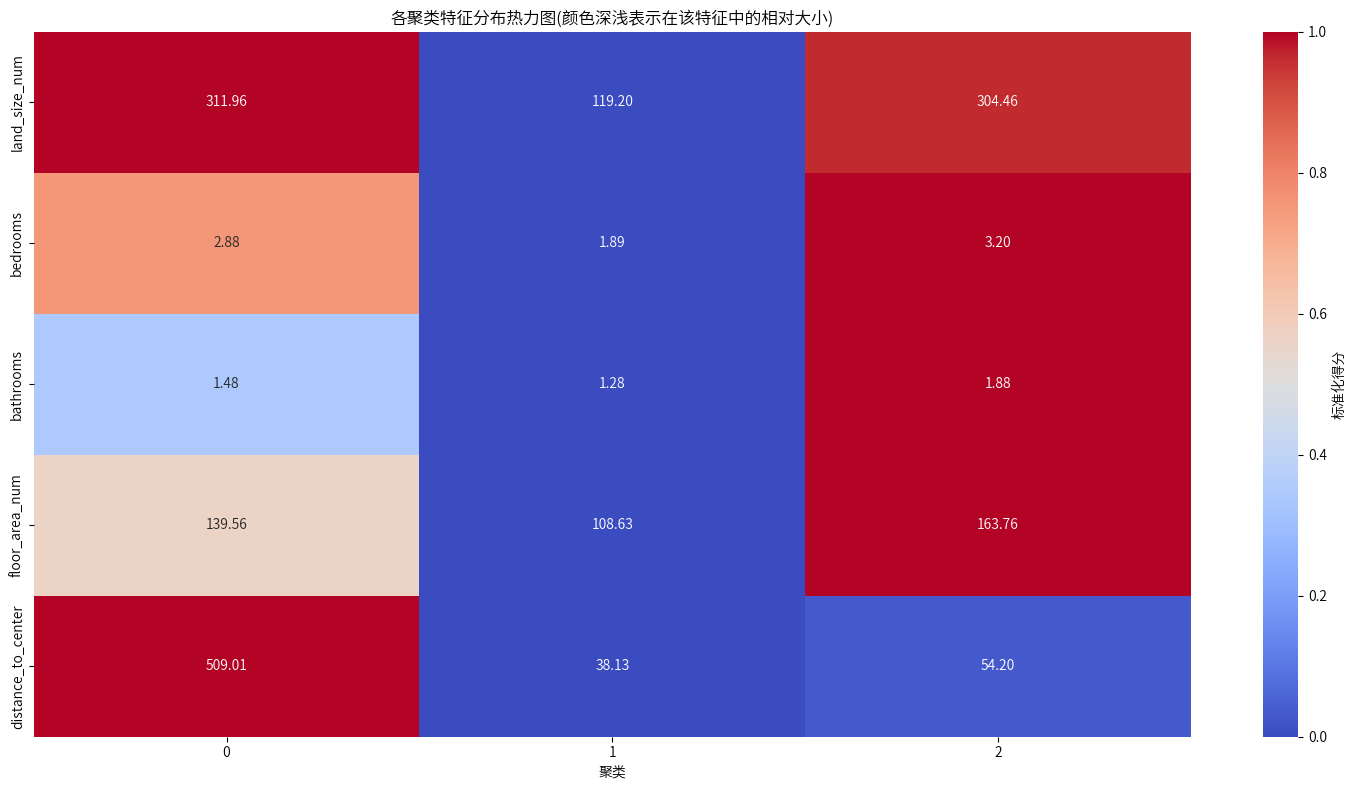
聚类 0:
土地面积:311.96(最高),代表该类房产多为大面积地块。
卧室数量:2.88(接近3卧室),房产以中型住宅为主。
浴室数量:1.48(接近1-2间),浴室数量较为普通。
楼面面积:139.56(中等),显示这些房产的实际使用面积较宽敞。
距离市中心:509.01 公里(远郊),表明这些房产主要分布在远离悉尼市区的区域。
聚类 1:
土地面积:119.20(最低),多为小型地块。
卧室数量:1.89(最低),多为1-2卧室的小型住宅。
浴室数量:1.28(最低),多为单间或1-2间浴室的小型住宅。
楼面面积:108.63(最小),显示该类房产更倾向于小型公寓或经济型住宅。
距离市中心:38.13 公里(最近),显示这些房产多分布在接近悉尼市区的区域。
聚类 2:
土地面积:304.46(接近聚类 0),代表房产以大面积地块为主。
卧室数量:3.20(最高),多为3卧室以上的住宅。
浴室数量:1.88(中等偏高),显示住宅通常有2间左右浴室。
楼面面积:163.76(最高),表明房产为宽敞的大型住宅。
距离市中心:54.20 公里(中间范围),可能分布于郊区或近郊区域。
7.结论基于对1000条房产数据的全面分析,本项目得出了以下主要结论:
数据清理:原始数据存在较严重的缺失和异常情况。经过严格的数据清洗,最终保留了990条完整样本和13个字段,确保后续分析的可靠性。
描述性分析:清洗后的数据反映了悉尼及其周边地区的房地产市场特点。市场以公寓(Unit)为主导,房产面积较小、卧室数量较少的房型占主流。此外,近年来房地产交易的活跃度显著提升,表现出市场热度上升的趋势。
聚类分析:通过K-Means聚类方法,将房产数据划分为以下三类:
聚类 0:以远郊地区的大型地块房产为主,空间较大但位置相对偏远。
聚类 1:多集中于市区或其附近的小型住宅,适合对地理位置要求较高的买家。
聚类 2:主要代表位于郊区的大型住宅,空间宽敞,适合家庭型需求。
